huggingface : https://huggingface.co/deepreinforce-ai/Ornith-1.0-35B-GGUF
공식문서 : https://deep-reinforce.com/ornith_1_0.html
한국블로그 소개 : https://javaexpert.tistory.com/1783
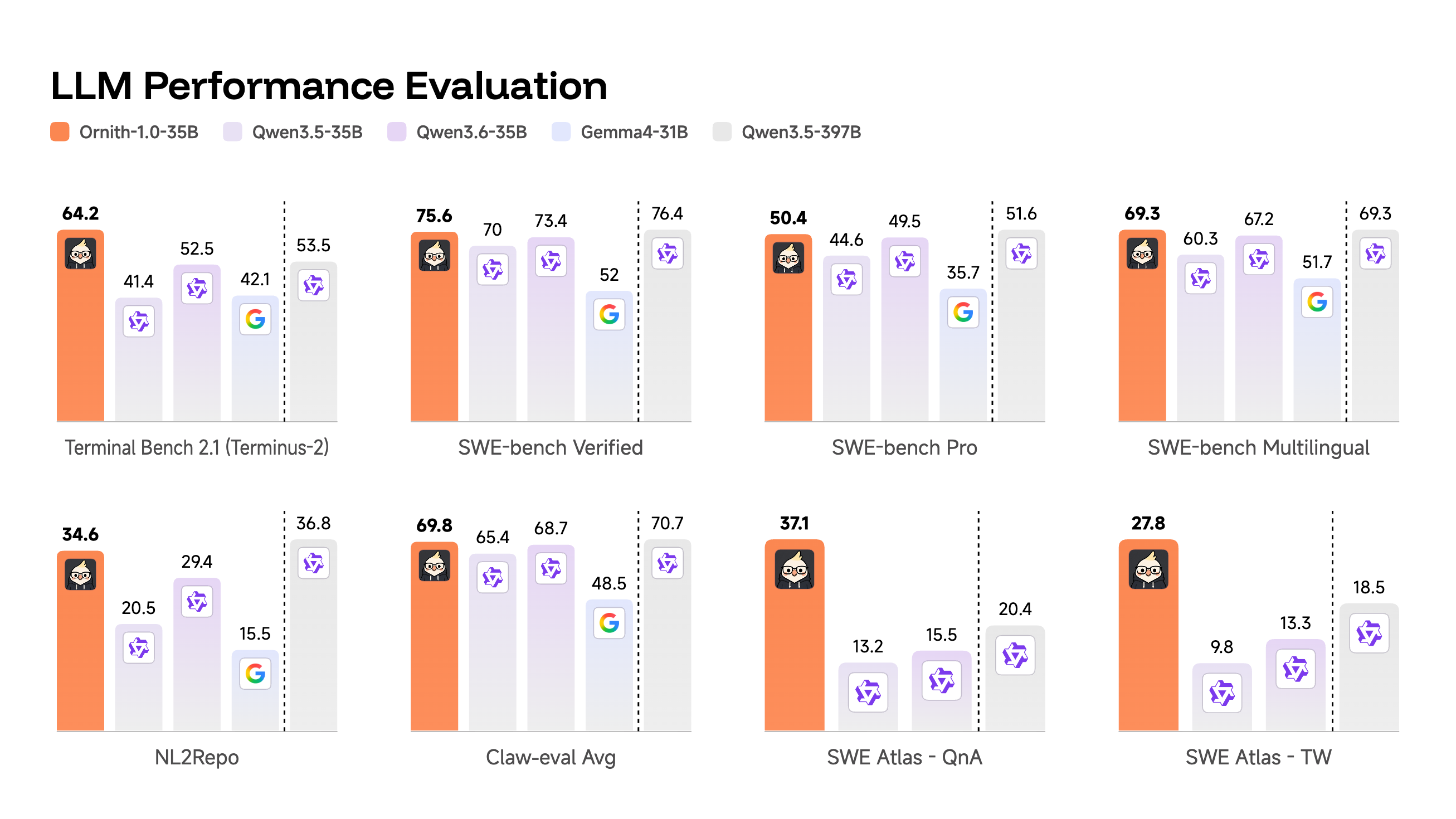
최첨단 코딩 에이전트 : 9B-Dense, 31B-Dense, 35B-MoE, 397B-MoE(Gemma 4 및 Qwen 3.5 기반 사후 학습) 버전으로 제공되며, Terminal-Bench 2.1, SWE-Bench, NL2Repo, OpenClaw와 같은 코딩 벤치마크에서 유사한 규모의 오픈 소스 모델 중 최고 수준의 성능을 달성합니다.
자체 개선 학습 프레임워크 : Ornith-1.0은 강화 학습(RL)을 활용하여 솔루션 도출 과정뿐만 아니라 해당 도출 과정을 이끄는 스캐폴드(scaffold)까지 학습합니다. 스캐폴드와 결과 솔루션을 동시에 최적화함으로써, 모델은 더 나은 탐색 경로를 발견하고 더 높은 품질의 솔루션을 생성합니다.
셀프 개선 한다는데 어떻게 적용되는지 이해가 잘 가지않고..
레딧형님들 리뷰로는 think 루프 돈다고 하네요.
Qwen3.5 기반 재학습이라 결국 또 다른 Qwen파생모델인 것 같습니다.
파생모델 써서 좋은 결과 얻은 적이 잘 없어서 별로 기대는 안되네요.
재미삼아 테스트 해보려구요.
huggingface : https://huggingface.co/deepreinforce-ai/Ornith-1.0-35B-GGUF
Dokumen Resmi : https://deep-reinforce.com/ornith_1_0.html
Pengenalan Blog Korea : https://javaexpert.tistory.com/1783
Agen Kode Terkini : Tersedia dalam versi 9B-Dense, 31B-Dense, 35B-MoE, dan 397B-MoE (Pelatihan lanjutan berdasarkan Gemma 4 dan Qwen 3.5), Ornith-1.0 mencapai kinerja terbaik di antara model open source dengan ukuran serupa pada benchmark pengkodean seperti Terminal-Bench 2.1, SWE-Bench, NL2Repo, dan OpenClaw.
Kerangka Kerja Pembelajaran Diri Sendiri : Ornith-1.0 menggunakan pembelajaran penguatan (RL) untuk mempelajari tidak hanya proses penyelesaian solusi tetapi juga kerangka yang memimpin proses tersebut. Dengan mengoptimalkan kerangka dan solusi hasil secara bersamaan, model dapat menemukan jalur eksplorasi yang lebih baik dan menghasilkan solusi dengan kualitas yang lebih tinggi.
Saya tidak terlalu mengerti bagaimana penerapan pembelajaran diri sendiri...
Menurut ulasan di Reddit, mereka mengatakan itu seperti loop berpikir.
Karena pelatihan ulang berdasarkan Qwen3.5, pada akhirnya ini adalah model turunan Qwen lainnya.
Saya belum pernah mendapatkan hasil yang baik dengan menggunakan model turunan, jadi saya tidak terlalu berharap banyak.
Saya akan mencobanya untuk bersenang-senang saja.
huggingface : https://huggingface.co/deepreinforce-ai/Ornith-1.0-35B-GGUF
Official documentation : https://deep-reinforce.com/ornith_1_0.html
Korean blog introduction : https://javaexpert.tistory.com/1783
Cutting-edge coding agent : Available in 9B-Dense, 31B-Dense, 35B-MoE, and 397B-MoE (Gemma 4 and Qwen 3.5 fine-tuned) versions, it achieves top performance among open-source models of similar scale on coding benchmarks such as Terminal-Bench 2.1, SWE-Bench, NL2Repo, and OpenClaw.
Self-Improving Learning Framework : Ornith-1.0 utilizes reinforcement learning (RL) to learn not only the solution derivation process but also the scaffold that guides it. By simultaneously optimizing the scaffold and the resulting solution, the model discovers better exploration paths and generates higher quality solutions.
I don't quite understand how self-improvement is applied...
According to Reddit reviews, it's said to use a think loop.
Since it's Qwen 3.5 fine-tuning, it seems to be another Qwen derivative model.
I haven't had much success using derivative models, so I'm not expecting much.
I'll try it out for fun.
